
How to Setup Docker for Azure Cognitive Services to Obtain Healthcare Text Analytics and HL7 FHIR Data


Upon completing this guide, you will successfully set up and have running a Docker container capable of processing unstructured medical text through HTTP requests by utilizing an Azure Cognitive Analytics Language Service in the cloud. The container will respond with healthcare-specific text analyses and also provide the FHIR representation of the input medical data.
Prerequisites
This tutorial assumes the following:
Docker is already installed and running.
You have access to an Azure account with the necessary permissions to create and configure Cognitive Language Services.
Pull the Docker Image
With your CLI of choice, use the following command to download the latest Docker image from Microsoft's Docker Hub:
docker pull mcr.microsoft.com/azure-cognitive-services/textanalytics/healthcare:latest
It'll then be listed from Docker Desktop's Images view:
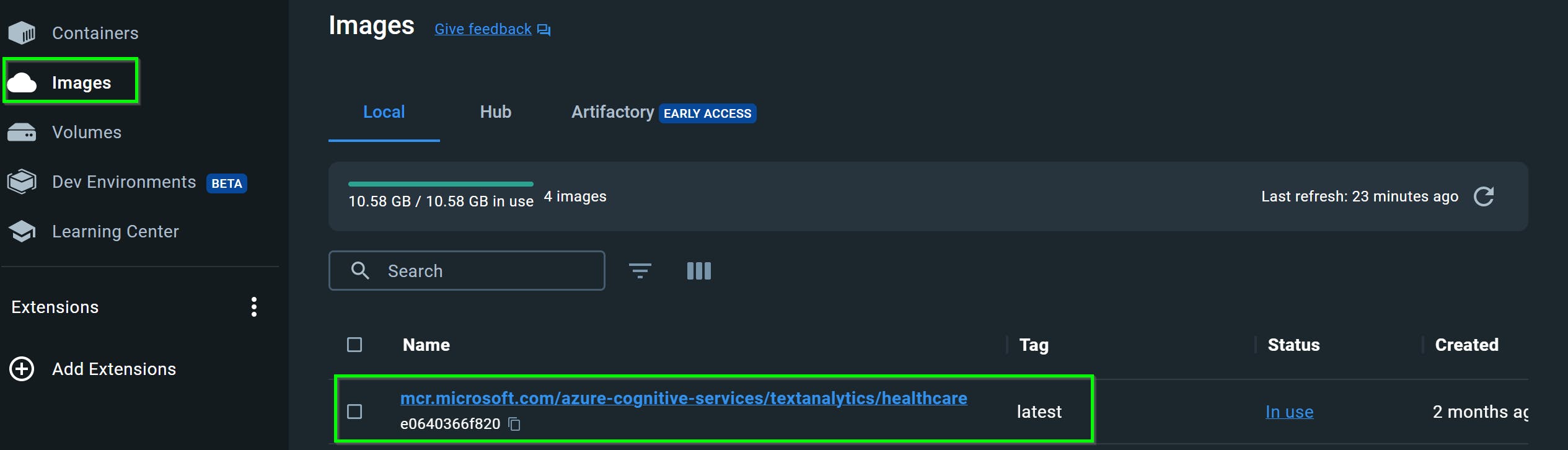
Alternatively, you can also check if the image was downloaded with
docker images --format "table {{.ID}}\t{{.Repository}}\t{{.Tag}}"
which will list all the Docker images on your machine.
Azure Portal: Creating the Cognitive Language Service
To analyze the input medical text, you'll first need to create and deploy a language service from Azure Portal.
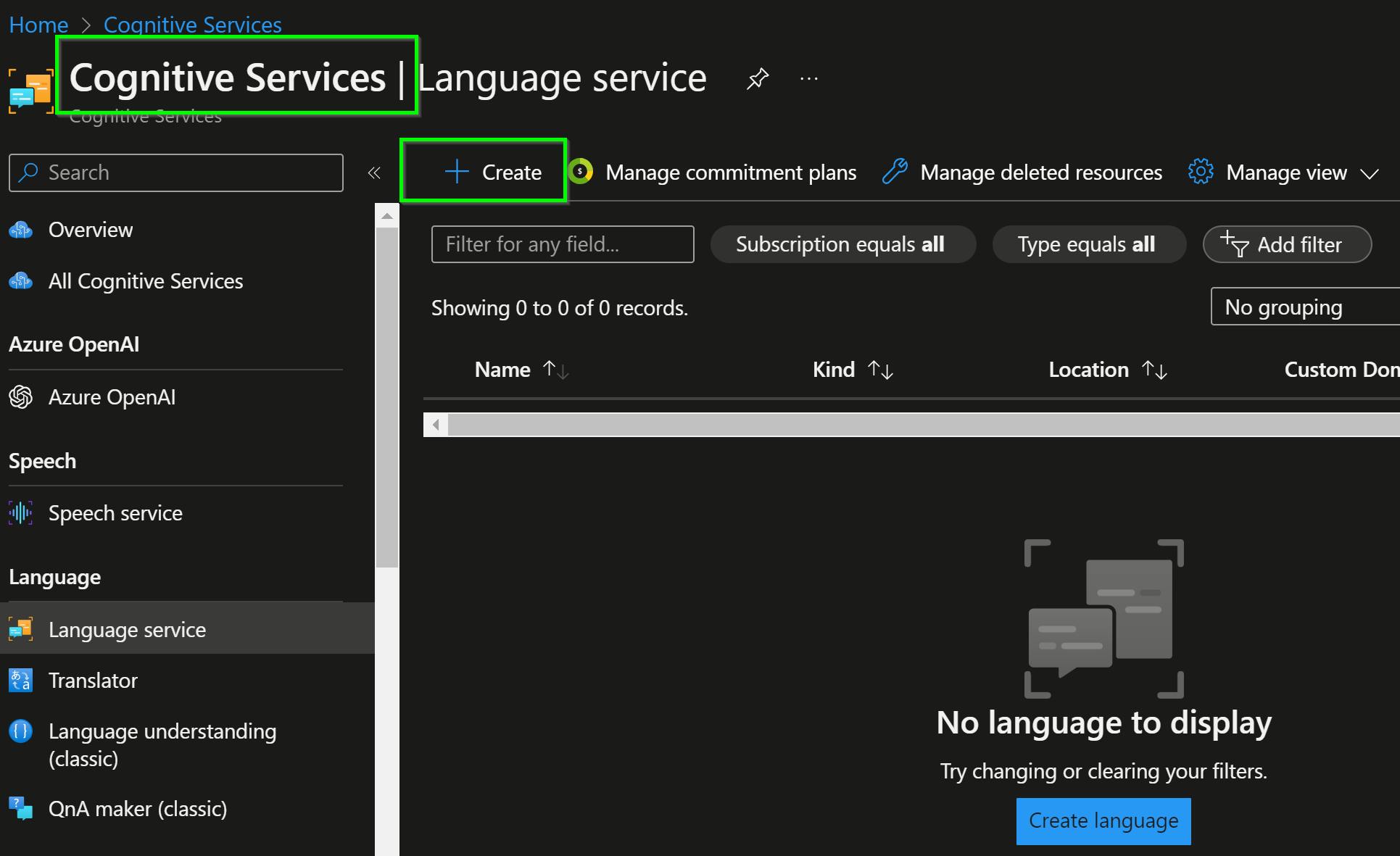
Fill out the following Create Language form and select "Review + create" to deploy the service.

Once created, there are two pieces of information from the service that you'll need to provide at the time of spinning up the Docker container:
Endpoint- The base URL of the API, obtained from the Overview page.
Access Key- Choose just one out of the two keys available from Keys and Endpoint.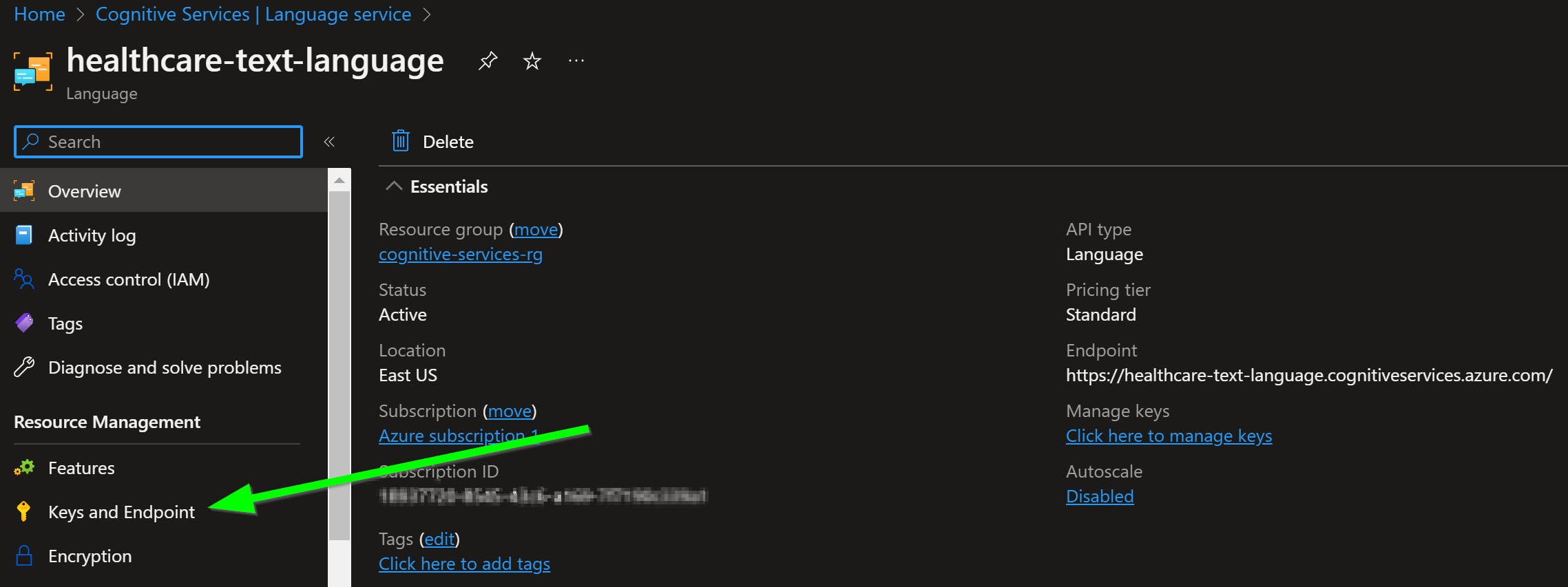
Starting the Docker Container
For the sake of this tutorial, to launch the container we'll use PowerShell :
docker run --rm -it -p 5000:5000 --cpus 6 --memory 12g `
mcr.microsoft.com/azure-cognitive-services/textanalytics/healthcare:latest `
Eula=accept `
rai_terms=accept `
Billing=<endpoint-from-azure-portal> `
ApiKey=<access-key-from-azure-portal>
Several things happen throughout initialization, including establishing billing,

kicking off a handful of processes,

and loading the NER (Named Entity Recognition) model.
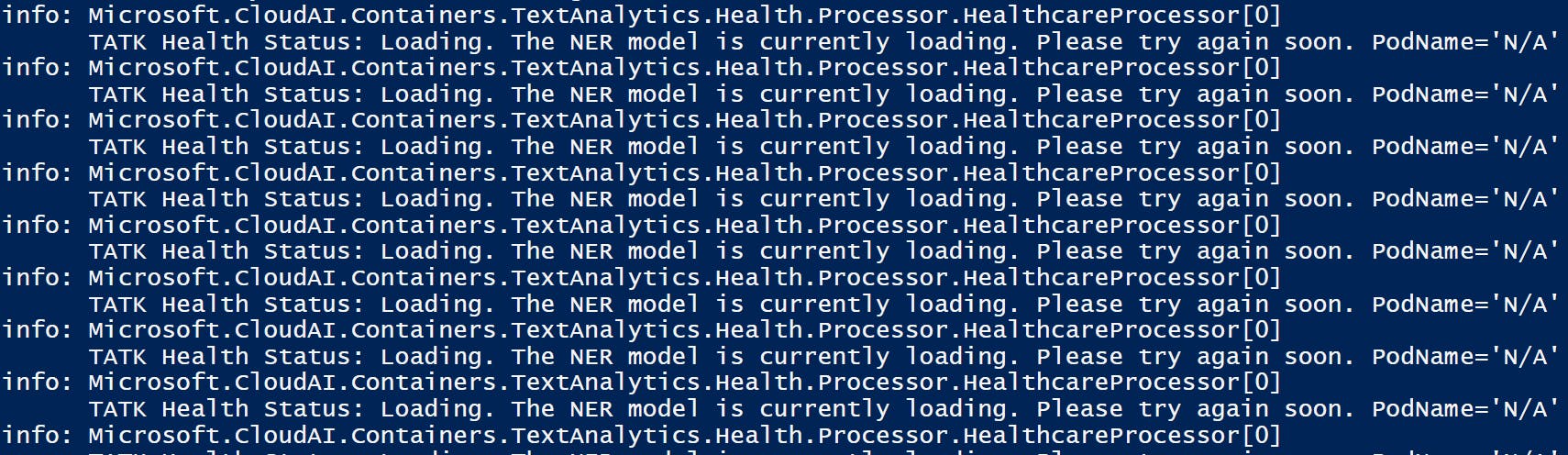
Once all the proper steps have been completed, the Docker container will be available on the specified port.
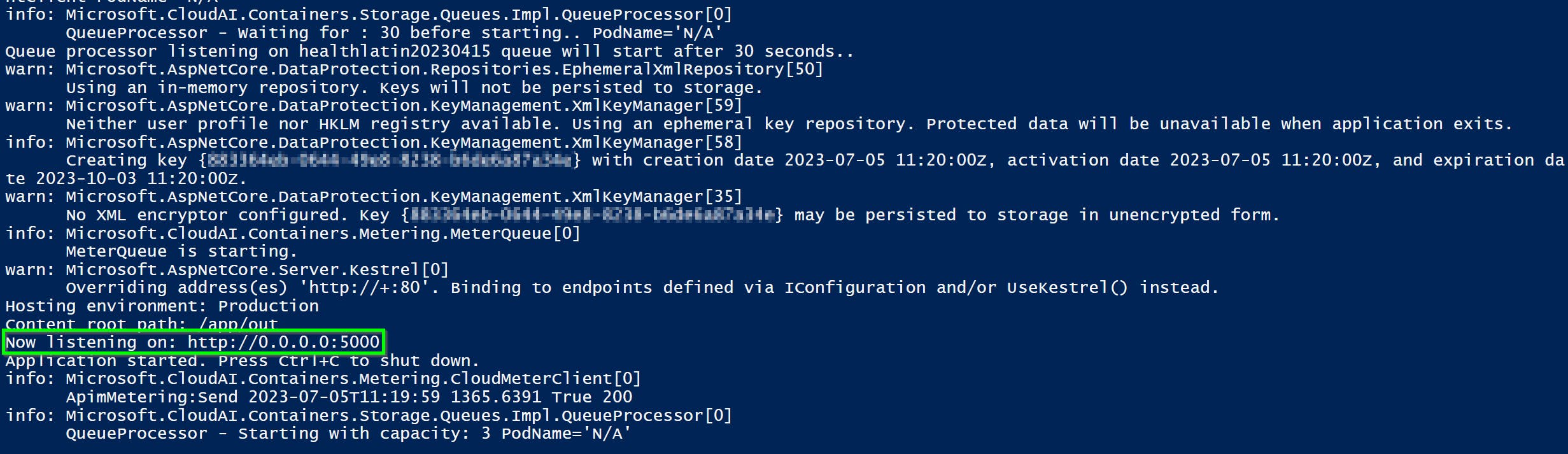
For a quick check, visit the reported URL with the path /demo (e.g., http://localhost:5000/demo). You should see the following UI that offers a text field to input freeform medical text to be analyzed.

There's also a Swagger page at http://localhost:5000/swagger/index.html.

With the Docker container now running on your host machine, next we're now going to take a step over to Postman to obtain the FHIR representation of the input medical text!
FHIR: A Quick Overview
Fast Healthcare Interoperability Resources (FHIR, pronounced "fire") is a standard for data exchange in the healthcare industry. Developed by the Health Level Seven International (HL7) healthcare standards organization, FHIR empowers the exchange of digital health information among software applications.
Unlike preceding standards, FHIR is designed for the internet age. It's based on modern web technologies such as RESTful APIs, JSON, and XML. This makes it easier to implement, as it uses familiar tools and concepts for anyone with a background in web development.
For engineers in healthcare, FHIR provides a set of clearly defined rules for how to represent and manipulate healthcare data. It works through "resources", which are units of healthcare data that can be as simple as a patient's name or as complex as a clinical observation.
These resources are used to create standardized data structures that can be understood and manipulated by any system implementing FHIR. For instance, a clinician might retrieve the Observation resources associated with a Patient to review the patient's latest lab results.
{
"resourceType": "Observation",
"id": "1234",
"status": "final",
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "8310-5",
"display": "Body temperature"
}
],
"text": "Body temperature"
},
"subject": {
"reference": "Patient/5678",
"display": "John Doe"
},
"effectiveDateTime": "2023-07-13T14:35:00-04:00",
"valueQuantity": {
"value": 37.2,
"unit": "C",
"system": "http://unitsofmeasure.org",
"code": "Cel"
},
"interpretation": {
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationInterpretation",
"code": "N",
"display": "Normal"
}
],
"text": "Normal"
}
}
Fetching FHIR Data using Postman
To obtain the FHIR representation of the unstructured input text, you need to use the Language API of the container instance which is API version 2022-04-01-preview or greater. That is, with each request, you'll need to provide 2022-04-01-preview as the api-version in the query parameters.
(You can use this Postman collection instead of building out your own if you like.)
Create a Job
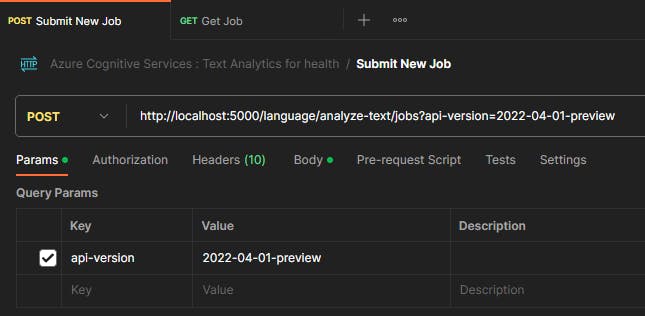
Make a POST request using the following details:
URL:
http://localhost:5000/language/analyze-text/jobs?api-version=2022-04-01-previewBody:
{ "analysisInput": { "documents": [ { "text": "The doctor prescribed 200mg Ibuprofen to be taken once a day in the afternoon with lunch.", "language": "en", "id": "1" } ] }, "tasks": [ { "taskName": "analyze 1", "kind": "Healthcare", "parameters": { "fhirVersion": "4.0.1" } } ] }
Assuming the request was successful (status of 202 Accepted), a job will be created and queued. Unfortunately, the response doesn't provide the newly created job details, so, to get the JobId you can check either the PowerShell output window or Logs from Docker Desktop (after selecting the running container).

Fetch the Job Details
With the JobId in hand, we can now make a GET request to fetch the job details.
- URL:
http://localhost:5000/language/analyze-text/jobs/:jobId?api-version=2022-04-01-preview&showStats=false&skip=0&top=20

A successful response will contain the result set of all keywords from the input text that are identified as medically relevant. With each keyword classification there's it's position in the text, the assigned category, and a confidenceScore.
{
"jobId": "f627b5f7-4d89-40cd-8921-59f9b5750a95",
"lastUpdateDateTime": "2023-07-14T03:50:38Z",
"createdDateTime": "2023-07-14T03:50:30Z",
"expirationDateTime": "2023-07-15T03:50:30Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "HealthcareLROResults",
"taskName": "analyze 1",
"lastUpdateDateTime": "2023-07-14T03:50:38.4718681Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"entities": [
{
"offset": 4,
"length": 6,
"text": "doctor",
"category": "HealthcareProfession",
"confidenceScore": 0.82
},
...
The FHIR Data
Just past the keyword classification results is the fhirBundle that contains the FHIR representation of the initial, unstructured input text.
"fhirBundle": {
"resourceType": "Bundle",
"id": "a0a67aa6-3295-4955-b129-bba0fac82450",
"meta": {
"profile": [
"http://hl7.org/fhir/4.0.1/StructureDefinition/Bundle"
]
},
"identifier": {
"system": "urn:ietf:rfc:3986",
"value": "urn:uuid:a0a67aa6-3295-4955-b129-bba0fac82450"
},
"type": "document",
"entry": [
{
"fullUrl": "Composition/d49b6f3e-2058-4699-aa97-39301cd629ab",
"resource": {
"resourceType": "Composition",
"id": "d49b6f3e-2058-4699-aa97-39301cd629ab",
"language": "en",
"status": "final",
"type": {
"coding": [
{
"system": "http://loinc.org",
"code": "11526-1",
"display": "Pathology study"
}
],
"text": "Pathology study"
},
"subject": {
"reference": "Patient/69a872b4-6c23-4233-a125-6b266153e57e",
"type": "Patient"
},
"encounter": {
"reference": "Encounter/cf94f029-3e88-4fc1-a58c-9b5ace8385c3",
"type": "Encounter",
"display": "unknown"
},
"date": "0001-01-01T00:00:00+00:00",
"author": [
{
"reference": "Practitioner/7a8e9092-a9d9-43d3-b604-5d065682c83d",
"type": "Practitioner",
"display": "Unknown"
}
],
"title": "Pathology study",
"section": [
{
"title": "(General)",
"code": {
"coding": [
{
"system": "",
"display": "Unrecognized Section"
}
],
"text": "(General)"
},
"author": [
{
"reference": "Practitioner/7a8e9092-a9d9-43d3-b604-5d065682c83d",
"type": "Practitioner",
"display": "Unknown"
}
],
"text": {
"status": "additional",
"div": "<div>\r\n\t\t\t\t\t\t\t<h1>(General)</h1>\r\n\t\t\t\t\t\t\t<p>The doctor prescribed 200mg Ibuprofen to be taken once a day in the afternoon with lunch.</p>\r\n\t\t\t\t\t</div>"
},
"entry": [
{
"reference": "List/ee4bec35-5529-42b5-8399-b29e2d451ddb",
"type": "List",
"display": "(General)"
}
]
}
]
}
},
...
And that's it!
If you made it this far, congratulations on completing the guide!!
Next Steps
In my next post [related to this solution], we'll take a more programmatic approach and start working with this analyzed data, in combination with FHIR datasets, to ultimately generate rich, dynamic, and responsive reports.
If you're interested in knowing when that's released, be sure to subscribe to my Hashnode newsletter or connect with me on LinkedIn.
Thanks and until next time, happy coding!